
Un ORM puede ser una de las mejores herramientas en al arranque de un proyecto , y puede convertirse en una pesadilla al mantenerlo. Analizamos los principales problemas que podemos encontrar en proyectos desarrollados con esta tecnología y cómo resolverlos.
Un ORM (Object Relational Mapping) es una abstracción de un modelo de datos relacional (la base de datos) con los objetos de una aplicación. Existen múltiples implementaciones de ORM, todas con sus bondades y sus defectos, pero antes de pasar a ellos, veamos un resumen de la relación amor-odio entre las aplicaciones y las bases de datos relacionales a lo largo del tiempo.
Históricamente, una aplicación se comunicaba con la una base de datos utilizando una interfaz propietaria. Es decir, la base de datos tenía una librería de acceso a la misma y uno la utilizaba para insertar datos, eliminarlos o seleccionarlos mediante SQL, que debía ser escrito cuidadosamente para mejorar el rendimiento y prevenir problemas de memoria. De estas tareas se encargaban los DBA (Data base Administrator) que debían tener un conocimiento profundo del lenguaje SQL.
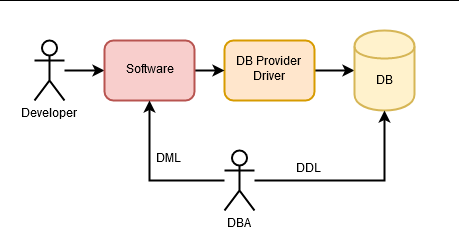
Con el tiempo, fueron apareciendo diferentes proveedores de bases de datos relacionales, y con ello la necesidad de abstraerse de las mismas. La idea era que, si se cambiaba el proveedor de base de datos, no hubiera que cambiar todo el acceso a datos de la aplicación. Esta necesidad se cubrió con ODBC (Open Data base Conectivity) y, posteriormente, con JDBC (Java Data base Conectivity). Los desarrolladores seguían necesitando a los DBA para escribir código SQL que aprovechara las funcionalidades de la base de datos sin perjudicar al rendimiento.
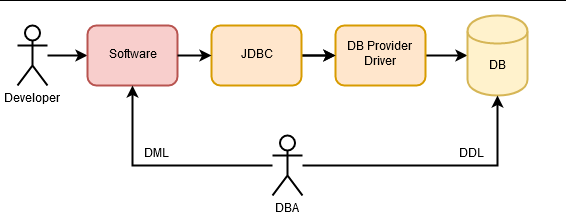
Más adelante, los desarrolladores empezamos a decidir sobre la base de datos por nosotros mismos (demasiado listos parecemos), y empiezan a aparecer los primeros ORM, que directamente mapean filas de las tablas de la base de datos en objetos dentro de las aplicaciones.
Estos primeros ORM (por ejemplo, apache Torque, que contra todo pronóstico sigue existiendo) se basaban en la generación de código a partir del esquema de la base de datos, y este código se volvía a generar con cada modificación en la misma. Igualmente, los ORMs empezaban a generar dinámicamente las consultas que se hacían a la base de datos, traduciendo código del lenguaje de origen en SQL.
Los DBA empezaban a caer en desuso, ya que los ORM parecía que estaban haciendo su tarea de optimizar las operaciones sobre la base de datos. Sus funciones acabaron delegadas a definir el modelo de datos, índices, vistas, y todo el aspecto del DDL (Data Definition Language), de forma que los ORM se encontraran «parte del trabajo hecho» para ejecutar DML (Data Manipulation Language).
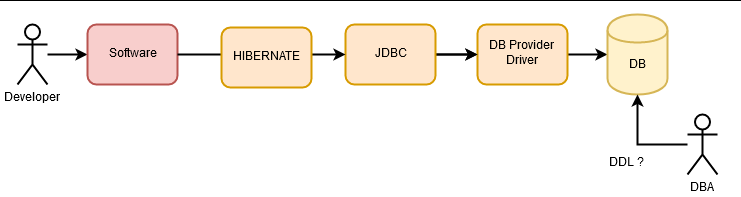
Y a día de hoy, tenemos ORMs con los que definimos toda la base de datos en código (Hibernate), incluyendo entidades, relaciones, índices e incluso vistas y a partir de esta definición podemos generar la base de datos completos. Con ello, el trabajo de DBA se convirtió en un análisis «a posteriori» de lo que pasaba en una aplicación. Mayormente, los DBA son la última línea de defensa ante una aplicación que da mal rendimiento en el acceso a datos. La frase más común de un DBA es «WTF!», al ver las consultas ejecutadas desde una aplicación.
Más adelante, hemos seguido abstrayéndonos de la base de datos, añadiendo JPA (Java Persistence API), una abstracción de la que Hibernate es una implementación
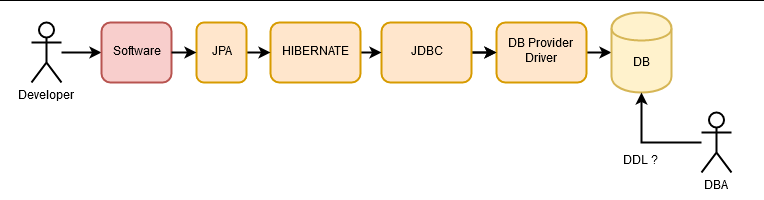
Poco después, Spring-Data, que es una abstracción sobre el acceso a datos.
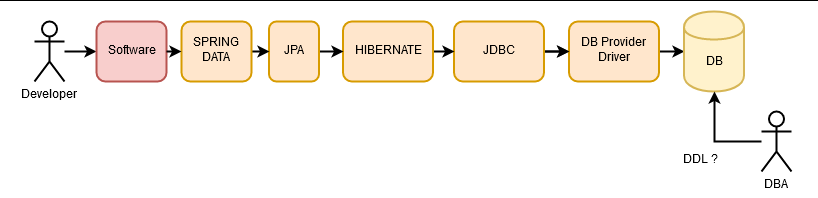
No se puede hablar de los ORM sin hablar un poco más de los DBA. Estos perfiles sabían SQL. Y lo sabían tan bien como un programador sabe Java o sabe PHP.
A día de hoy, nos cuesta trabajo pensar en un excelente programador Java que haga excelentes servidores con Ruby on Rails o excelentes frontends en Angular. Y eso se debe a que nos vamos especializando en cada vertical de conocimiento. Y la vertical de conocimiento de SQL la hemos «asimilado» dentro del lenguaje de programación de la aplicación, o eso nos creemos.
¿Cómo llega esto a ser un problema? Fácil, los ORMs se han convertido en herramientas muy potentes que nos ocultan «demasiado» (y demasiado bien) la base de datos, permitiéndonos hacer en código (de aplicación) operaciones que se convierten en verdaderas catástrofes desde el punto de vista de SQL.
A continuación, veamos algunos de los problemas más comunes que pueden provocar el suicidio del desarrollador de mantenimiento.
Las consultas que traen todo, la casa a cuestas.
No es raro en arquitecturas que hacen uso de ORM encontrar que la comodidad de traer objetos de la base de datos en una línea, nos permite inadvertidamente generar problemas de rendimiento, tomemos el siguiente ejemplo.
Dada la entidad:
@Entity
@Table(name = "customers")
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
private String name;
private String email;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
}Y el siguiente repositorio (Spring-Data):
@Repository public interface CustomerRepository extends CrudRepository<Customer, Long> { }El siguiente código que obtiene el nombre del objeto customer podría ser correcto.
Customer foundCustomer = customerRepository.findById(userId).get();
System.out.println("Customer name is:" + foundCustomer.getName());Pero lo que está sucediendo es que, como programadores, estamos aprovechando los métodos existentes (mágicos) de CrudRepository para obtener el objeto por el id. Y de ahí, obtener el nombre. Somos programadores vagos (y eso es bueno), pero no sabemos lo que está pasando detrás de la magia (y eso es malo). Y lo que está sucediendo es esto:
select customer0_.id as id1_0_0_, customer0_.email as email2_0_0_, customer0_.name as name3_0_0_ from customers customer0_ where customer0_.id=?Es decir, aunque nuestro código tan solo quiere obtener el nombre del usuario (y nada más) estamos trayendo la fila entera de la base de datos. Y esto sí es un problema si el día de mañana alguien añade campos al objeto customer, ya que los consultaríamos de manera inadvertida.
¿Cuál es la solución? La solución es sencilla: la base de datos es un sitio al que ir a consultar exactamente la información que se quiere obtener de la forma más directa posible, aunque requiera más código.
@Query("SELECT c.name from Customer c where c.id=:id")
String getCustomerName(@Param("id") Long id);Los updates parciales que se convierten en totales, el por si acaso.
Ejecutamos el siguiente código:
// Create customer
Customer customer=new Customer();
customer.setEmail("[email protected]");
customer.setName("John Doe");
customerRepository.save(customer);
// Search same user by id
Customer foundCustomer=customerRepository.findById(customer.getId()).get();
foundCustomer.setName("Other name");
// Save same user again
customerRepository.save(foundCustomer);¿Parece correcto? Si, desde el punto de vista de un programador no parece estar pasando nada grave, pero veamos que código se está ejecutando más abajo, en la capa JDBC
// Create customer
Hibernate: insert into customers (email, name, id) values (?, ?, ?)
// Search same user by id
Hibernate: select customer0_.id as id1_0_0_, customer0_.email as email2_0_0_, customer0_.name as name3_0_0_ from customers customer0_ where customer0_.id=?
// Save same user again
Hibernate: select customer0_.id as id1_0_0_, customer0_.email as email2_0_0_, customer0_.name as name3_0_0_ from customers customer0_ where customer0_.id=?
Hibernate: update customers set email=?, name=? where id=?Ups, ¿qué ha pasado? Bueno, han pasado dos cosas en el último save. La primera es que para resolver la llamada a save, la librería se defiende que nosotros, suponiendo que no sabemos lo que hacemos, y se pregunta si lo que queremos hacer es un update, o un insert de un objeto nuevo. Así que, para curarse en salud, hace una select por el id. Y, dado que el objeto existe, decide (correctamente) que lo que queremos hacer es un update. ¿Pero un update de qué? Pues aquí tenemos el segundo dilema, hacemos un update de todo.
Doctor, ¿es grave? Bueno, puede que hoy no. En este caso lo pasamos por alto porque nuestra entidad no pesa nada, y vamos a notar poco o ningún impacto. Desgraciadamente, esta es una de esas enfermedades del código fuente que se nos puede ir de las manos… Veamos qué pasa si otro programador B decide añadir un campo a la entidad.
@Lob
@Column(length = 10240)
private byte[] userIcon;¿Que sucede ahora con el código del programador A? Pues lo que sucede es que el último save produce el siguiente sql:
Hibernate: select customer0_.id as id1_0_0_, customer0_.email as email2_0_0_, customer0_.name as name3_0_0_, customer0_.user_icon as user_ico4_0_0_ from customers customer0_ where customer0_.id=?
Hibernate: update customers set email=?, name=?, user_icon=? where id=?
Es decir, vamos a la base de datos a por el array de bytes y lo volvemos a enviar para actualizarlo. Acabamos de ampliar (y no poco), el uso de la red para, simplemente, actualizar el nombre del usuario. Y eso sí que es un problema para el programador A, que sin saber muy bien el porqué, su función tarda 3 veces más en resolverse.
¿A que se debe esto? Pues se debe a que «un gran poder conlleva una gran responsabilidad». Si utilizamos un ORM, en este caso SpringData/JPA/Hibernate, tenemos que tener en cuenta que lo que no programamos, él se lo debe inventar «de la mejor forma que pueda» y normalmente, sin la información suficiente, ya que esa información la tiene el programador, que si apuesta por reducir la cantidad de código (y eso es bueno) puede caer en la trampa de que el software final es totalmente ineficiente (y eso es malo).
¿Qué solución hay? Fácil. Por mucho que una capa de abstracción nos oculte la base de datos, nosotros tenemos que seguir comportándonos como DBA. Esto es, mirar qué es lo que va a pasar en la base de datos y actuar en consecuencia. Si lo que quería hacer el programador A es hacer un update del nombre a partir del ID, debería haber hecho un «UPDATE customers SET name=? WHERE ID=? «, que en JPA habría sido un método bastante sencillo:
@Modifying
@Transactional
@Query("UPDATE Customer c set c.name=:name where c.id=:id")
void updateCustomerSetName(@Param("id") Long id,@Param("name") String name);
Insertando múltiples filas, poco a poco
Con un ORM , en este caso, JPA , tenemos la posibilidad de definir las relaciones entre dos tablas, por ejemplo, nuestra tabla CUSTOMER podría tener asociada una tabla ORDER en la que almacenar los pedidos de dicho usuario. A simple vista está claro que hay una relación entre ambos objetos, para una fila de Customer, podríamos tener 0 o más filas de Order.
Supongamos que nuestro modelo tiene además de la tabla Customer, una tabla Order, cuya clase dentro de la aplicación es así:
@Entity
@Table(name = "orders")
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name="customerId")
private Customer customer;
private Double total=0.0;
// Setters and Getters
}
y nuestra clase Customer sería así:
package com.viafirma.blog.orm.entity;
import javax.persistence.*;
import java.util.List;
@Entity
@Table(name = "customers")
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
private String name;
private String email;
@OneToMany(mappedBy = "customer",cascade = CascadeType.ALL)
private List orders;
// Setters and Getters
}Probemos a crear un objeto Customer y asociarle objetos Order:
Customer customer = new Customer();
customer.setName("Name");
customer.setEmail("Email");
List orders=new ArrayList();
for(int i=0;i!=10;i++){
Order order=new Order();
order.setCustomer(customer);
orders.add(order);
}
customer.setOrders(orders);
customerRepository.save(customer);Y veamos el SQL resultado:
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: insert into customers (email, name, id) values (?, ?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)Vemos que JPA ha ido obteniendo los ids de los objetos que va a insertar, inserta el objeto Customer y luego inserta los objetos Order en una secuencia de inserts. Pero… ¿se puede hacer mejor? Pues si, es posible mediante un viejo amigo de los DBA que es el insert en batch, que con una única sentencia se pueden insertar multiples filas en la base de datos, pero esa funcionalidad no está disponible en JPA por defecto, es necesario indicarla de forma explícita a la implementación en este caso, de hibernate, por ejemplo , con Spring lo indicaríamos en el application.properties
spring.jpa.properties.hibernate.jdbc.batch_size=5
spring.jpa.properties.hibernate.order_inserts=true
spring.jpa.properties.hibernate.order_updates=true
spring.jpa.properties.hibernate.jdbc.batch_versioned_data=trueen la propiedad batch_size indicaríamos en bloques de cuantas entidades habría que realizar los inserts, en este caso, de bloques 5 en 5. Con lo que nos quitaríamos sorpresas inesperadas de lentitud en inserts multiples.
Construcción de SQL en código, la urticaria.
Supongamos el siguiente código:
StringBuilder sb=new StringBuilder("<html>")
.append("<head>")
.append("</head>")
.append("<body>");
for(int i=0;i!=10;i++){
sb.append("<p>Hello paragraph "+i+"</p>");
}
sb.append("</body>")
.append("</html>");
¿Alguien ha notado una vibración en la fuerza, un brote de sentido arácnido o ardores? Si es así, se debe a que tenemos dos lenguajes «Java» y «HTML» mezclados íntimmente en el mismo código, de forma que cambiar algo del HTML implica modificar el fuente Java y lo que es peor, estamos suponiendo que el desarrollador Java sabe de HTML, lo cual es cuando menos una suposición ( El ejemplo es sencillo, pero sé que me entendéis ).
Ahora veamos un ejemplo de JPQL dentro de código:
List<Customer> foundCustomer=em.createQuery(
"SELECT c from Customer c Where c.name like :name", Customer.class)
.setParameter("name","Name")
.getResultList();O simplificando:
@Query("SELECT c from Customer c where c.name=:name")
List findCustomersByName(@Param("name") String name);¿Porqué este código nos produce menos alarmas? ¿No es el mismo caso? Estamos mezclando dos lenguajes, JPQL (o SQL si fuera una query nativa) con Java y exactamente con las mismas consecuencias, un programador Java no tiene porqué hacer excelentes queries, y desde luego, incrustar codigo SQL dentro de Java no hace que sea muy cómodo que un DBA pueda analizarlas.
¿Podemos evitar esto? Pues si, JPA nos permite editar las consultas en ficheros externos a la fuente, en un fichero de nombre jpa-named-queries.properties dentro de un directorio META-INF en los recursos del proyecto, con una lista de clave valor de la siguiente forma:
Customer.findCustomersByName=SELECT c from Customer c Where c.name like ?1Y en código, dentro de un repositorio, bastaría con indicar el nombre del método que deberá coincidir con la propiedad en el archivo, con el formato de [entidad].[nombre_metodo]
@Repository
public interface CustomerRepository extends CrudRepository<Customer, Long> {
List<Customer> findCustomersByName(String name);
}De esta forma mantendríamos el código sql separado del fuente java, en un lugar centralizado y fácil de revisar por un DBA
Las selects infinitas, o cómo quedarse sin memoria en un SELECT.
Supongamos que tenemos que generar un informe en un fichero con los resultados de una consulta, un ORM nos invitaría hacer algo así:
Iterable<Customer> customers=customerRepository.findAll();
saveToDisk(customers)Este código tiene una ventaja: es corto y directo. Y una gran desventaja: es una visión muy simplificada del problema.
Supongamos que nuestro objeto customer fuera relativamente grande. Digamos 16kb. Y que en la tabla, después de 3 años en producción, fueran 1500000. En una única llamada, ocuparíamos 20Mb de memoria y el recolector de basura debería eliminarla al finalizar el guardado a disco. Esto se debe a que el ORM nos da una gran libertad a la hora de lanzar esa consulta, pero si somos poco responsables, ocasionaremos graves problemas de rendimiento.
¿Alguna forma de resolverlo? Si, procesando las filas de la consulta 1 a 1.¿Cómo? Pues primero, olvidándote de JPA, ya que no vas a encontrar la solución ahí. Tenemos dos opciones:
- Nos pasamos al mundo de JDBC y recorremos el resultado con un ResultSet.
- Hacerlo directamente con Hibernate.
Con Hibernate, sería algo así:
StatelessSession session = ((Session) em.getDelegate()).getSessionFactory().openStatelessSession();
Query query = session
.createQuery("SELECT c FROM Customer c ");
query.setFetchSize(1000);
query.setReadOnly(true);
ScrollableResults results = query.scroll(ScrollMode.FORWARD_ONLY);
while (results.next()) {
Customer customer=(Customer)results.get(0);
saveToDisk(customer);
}
results.close();
session.close();Conclusión
En resumen, el uso de ORM (Spring-Daa / JPA / Hibernate) nos abstrae de la base de datos intentando hacer que nuestro trabajo se simplifique lo máximo posible, pero el desarrollo de software que se comunica con una base de datos requiere en muchos casos optimizaciones que no casan del todo bien con la simplificación. Y sin estas optimizaciones los desarrollos que se realizan rápidamente gracias a la asbtracción provocan graves problemas de memoria y de rendimiento general durante el mantenimiento.
La mejor herramienta que se puede utilizar durante el desarrollo con JPA/Hibernate es habilitar del log de SQL, la inspección directa de las consultas, y comprender el porqué nuestro ORM las ejecuta, y en caso de duda, desenterrar un DBA que seguro que sabe lo que sucede.