
An ORM can be one of the best tools at the start of a project, and it can become a nightmare to maintain. We analyse the main problems that can be found in projects developed with this technology and how to solve them.
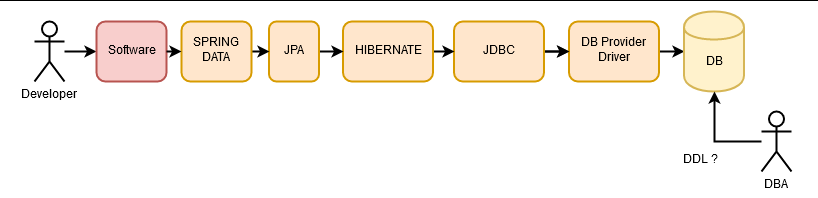
An ORM (Object Relational Mapping) is an abstraction of a relational data model (the database) with the objects of an application. There are multiple ORM implementations, all with their strengths and weaknesses, but before we move on to them, let’s take a look at a summary of the love-hate relationship between applications and relational databases over time.
Historically, an application communicated with a database using a proprietary interface. That is, the database had a database access library and one used it to insert, delete or select data using SQL, which had to be carefully written to improve performance and prevent memory problems. These tasks were performed by DBAs (Database Administrators) who had to have a deep knowledge of the SQL language.
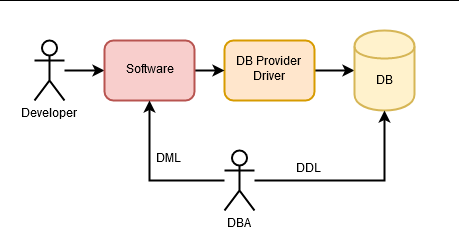
Over time, different relational database vendors emerged, and with them the need to abstract from relational databases. The idea was that, if the database provider was changed, the entire data access of the application would not have to be changed. This need was met with ODBC (Open Database Connectivity) and later with JDBC (Java Database Connectivity). Developers still needed DBAs to write SQL code that would take advantage of database functionality without compromising performance.
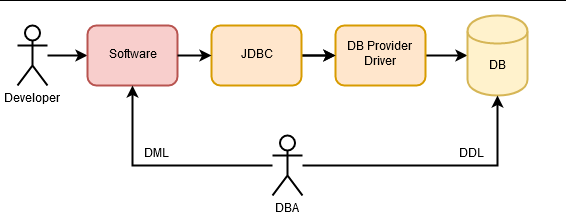
Later on, we developers started to decide about the database by ourselves (we seem to be too smart), and the first ORMs started to appear, which directly mapped rows of the database tables into objects inside the applications.
These first ORMs (for example, apache Torque, which against all odds still exists) were based on the generation of code from the database schema, and this code was re-generated with each modification to the database. Similarly, ORMs started to dynamically generate queries to the database, translating source language code into SQL.
DBAs were starting to fall into disuse, as ORMs seemed to be doing their job of optimizing database operations. Their functions ended up being delegated to defining the data model, indexes, views, and the whole DDL (Data Definition Language) aspect, so that the ORMs found themselves “part of the job done” to execute DML (Data Manipulation Language).
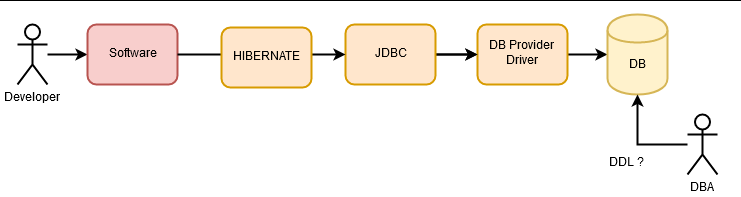
And today, we have ORMs with which we define the entire database in code (Hibernate), including entities, relationships, indexes and even views, and from this definition we can generate the entire database. With this, the DBA work became an “a posteriori” analysis of what was happening in an application. Mostly, DBAs are the last line of defense against an application that gives bad performance in data access. The most common phrase of a DBA is “WTF!” when looking at the queries executed from an application.
Further on, we have continued to abstract from the database, adding JPA (Java Persistence API), an abstraction of which Hibernate is an implementation.
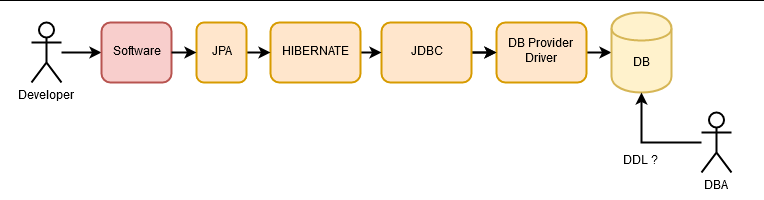
Shortly after, Spring-Data, which is an abstraction about data access.
You can’t talk about ORMs without talking a little more about DBAs. These profiles knew SQL. And they knew it as well as a programmer knows Java or PHP.
Nowadays, it is hard to think of an excellent Java programmer who makes excellent servers with Ruby on Rails or excellent frontends in Angular. And that is because we are specializing in each vertical of knowledge. And the SQL knowledge vertical has been “assimilated” into the application programming language, or so we think.
How does this become a problem? Easy, ORMs have become very powerful tools that hide us “too much” (and too well) the database, allowing us to do in (application) code operations that become real catastrophes from the SQL point of view.
Next, let’s look at some of the most common problems that can lead to maintenance developer suicide.
Consultations that bring everything, the house on their shoulders.
It is not uncommon in architectures that make use of ORM to find that the convenience of bringing database objects in one line inadvertently allows us to generate performance problems, take the following example.
Given the entity:
@Entity
@Table(name = "customers")
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
private String name;
private String email;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
}And the following repository (Spring-Data):
@Repository public interface CustomerRepository extends CrudRepository { } The following code that gets the name of the customer object could be correct.
Customer foundCustomer = customerRepository.findById(userId).get();
System.out.println("Customer name is:" + foundCustomer.getName());But what is happening is that, as programmers, we are leveraging existing (magic) CrudRepository methods to get the object by id. And from there, get the name. We are lazy programmers (and that’s good), but we don’t know what’s going on behind the magic (and that’s bad). And what is happening is this:
select customer0_.id as id1_0_0_, customer0_.email as email2_0_0_, customer0_.name as name3_0_0_ from customers customer0_ where customer0_.id=?That is to say, although our code only wants to obtain the user’s name (and nothing else) we are bringing the entire row from the database. And this is a problem if tomorrow someone adds fields to the customer object, since we would consult them inadvertently.
What is the solution? The solution is simple: the database is a place to go to consult exactly the information you want to obtain in the most direct way possible, even if it requires more code.
@Query("SELECT c.name from Customer c where c.id=:id")
String getCustomerName(@Param("id") Long id);Partial updates that become total updates, just in case.
We execute the following code:
// Create customer
Customer customer=new Customer();
customer.setEmail("[email protected]");
customer.setName("John Doe");
customerRepository.save(customer);
// Search same user by id
Customer foundCustomer=customerRepository.findById(customer.getId()).get();
foundCustomer.setName("Other name");
// Save same user again
customerRepository.save(foundCustomer);Does it look right? Yes, from a programmer’s point of view there doesn’t seem to be anything serious going on, but let’s see what code is running below, in the JDBC layer
// Create customer
Hibernate: insert into customers (email, name, id) values (?, ?, ?)
// Search same user by id
Hibernate: select customer0_.id as id1_0_0_, customer0_.email as email2_0_0_, customer0_.name as name3_0_0_ from customers customer0_ where customer0_.id=?
// Save same user again
Hibernate: select customer0_.id as id1_0_0_, customer0_.email as email2_0_0_, customer0_.name as name3_0_0_ from customers customer0_ where customer0_.id=?
Hibernate: update customers set email=?, name=? where id=?Oops, what happened? Well, two things happened in the last save. The first one is that to solve the call to save, the library defends that we, supposing that we don’t know what we do, and it wonders if what we want to do is an update, or an insert of a new object. So, to cure itself, it makes a select by the id. And, given that the object exists, it decides (correctly) that what we want to do is an update. But an update of what? Well, here we have the second dilemma, we do an update of everything.
Doctor, is it serious? Well, maybe not today. In this case we overlook it because our entity weighs nothing, and we’re going to notice little or no impact. Unfortunately, this is one of those source code ailments that can get out of hand…. Let’s see what happens if another programmer B decides to add a field to the entity.
@Lob
@Column(length = 10240)
private byte[] userIcon;What happens now with the code of programmer A? Well, what happens is that the last save produces the following sql:
Hibernate: select customer0_.id as id1_0_0_, customer0_.email as email2_0_0_, customer0_.name as name3_0_0_, customer0_.user_icon as user_ico4_0_0_ from customers customer0_ where customer0_.id=?
Hibernate: update customers set email=?, name=?, user_icon=? where id=?
That is, we go to the database to get the array of bytes and send it back to update it. We have just extended (and not a little), the use of the network to simply update the user’s name. And that is a problem for the programmer A, who without knowing why, his function takes 3 times longer to be solved.
Why is this? Because “with great power comes great responsibility”. If we use an ORM, in this case SpringData/JPA/Hibernate, we have to take into account that what we do not program, he must invent it “the best way he can” and normally, without enough information, since that information is held by the programmer, who if he bets on reducing the amount of code (and that’s good) can fall into the trap that the final software is totally inefficient (and that’s bad).
What is the solution? Easy. No matter how much an abstraction layer hides the database from us, we still have to behave as a DBA. That is, look at what is going to happen in the database and act accordingly. If what programmer A wanted to do is to update the name from the ID, he should have done an “UPDATE customers SET name=? WHERE ID=? “, which in JPA would have been a fairly simple method:
@Modifying
@Transactional
@Query("UPDATE Customer c set c.name=:name where c.id=:id")
void updateCustomerSetName(@Param("id") Long id,@Param("name") String name);
Inserting multiple rows, bit by bit
With an ORM , in this case, JPA , we have the possibility of defining the relationships between two tables, for example, our CUSTOMER table could have an associated ORDER table in which to store the orders of that user. At first glance it is clear that there is a relationship between both objects, for a Customer row, we could have 0 or more rows of Order.
Let’s suppose that our model has besides the Customer table, an Order table, whose class inside the application is like this:
@Entity
@Table(name = "orders")
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name="customerId")
private Customer customer;
private Double total=0.0;
// Setters and Getters
}
and our Customer class would be like this:
package com.viafirma.blog.orm.entity;
import javax.persistence.*;
import java.util.List;
@Entity
@Table(name = "customers")
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
private String name;
private String email;
@OneToMany(mappedBy = "customer",cascade = CascadeType.ALL)
private List orders;
// Setters and Getters
}Let’s try to create a Customer object and associate Order objects to it:
Customer customer = new Customer();
customer.setName("Name");
customer.setEmail("Email");
List orders=new ArrayList();
for(int i=0;i!=10;i++){
Order order=new Order();
order.setCustomer(customer);
orders.add(order);
}
customer.setOrders(orders);
customerRepository.save(customer);And let’s see the SQL result:
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
Hibernate: insert into customers (email, name, id) values (?, ?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)
Hibernate: insert into orders (customer_id, id) values (?, ?)We see that JPA has been obtaining the ids of the objects to be inserted, inserts the Customer object and then inserts the Order objects in a sequence of inserts. But… can it be done better? Well yes, it is possible by means of an old friend of the DBA that is the insert in batch, that with a single sentence you can insert multiple rows in the database, but that functionality is not available in JPA by default, it is necessary to indicate it explicitly to the implementation in this case, of hibernate, for example, with Spring we would indicate it in the application.properties.
spring.jpa.properties.hibernate.jdbc.batch_size=5
spring.jpa.properties.hibernate.order_inserts=true
spring.jpa.properties.hibernate.order_updates=true
spring.jpa.properties.hibernate.jdbc.batch_versioned_data=truein the batch_size property we would indicate in blocks of how many entities would have to make the inserts, in this case, of blocks 5 in 5. With what we would remove unexpected surprises of slowness in multiple inserts.
Construction of SQL in code, hives.
Assume the following code:
StringBuilder sb=new StringBuilder("")
.append("")
.append("")
.append("");
for(int i=0;i!=10;i++){
sb.append("Hello paragraph "+i+"
");
}
sb.append("")
.append("");
Has anyone noticed a vibration in the force, an outbreak of spidery sense or burning? If so, it is because we have two languages “Java” and “HTML” intimately mixed in the same code, so that changing something of the HTML implies modifying the Java source and what is worse, we are assuming that the Java developer knows HTML, which is at least an assumption ( The example is simple, but I know you understand me ).
Now let’s see an example of JPQL inside code:
List foundCustomer=em.createQuery(
"SELECT c from Customer c Where c.name like :name", Customer.class)
.setParameter("name","Name")
.getResultList(); Or to simplify:
@Query("SELECT c from Customer c where c.name=:name")
List findCustomersByName(@Param("name") String name);Why does this code produce less alarms, isn’t it the same case? We are mixing two languages, JPQL (or SQL if it were a native query) with Java and with exactly the same consequences, a Java programmer does not have to make excellent queries, and of course, embedding SQL code inside Java does not make it very comfortable for a DBA to parse them.
Can we avoid this? Yes, JPA allows us to edit the queries in files external to the source, in a file named jpa-named-queries.properties inside a META-INF directory in the project resources, with a list of key value as follows:
Customer.findCustomersByName=SELECT c from Customer c Where c.name like ?1And in code, inside a repository, it would be enough to indicate the name of the method that must match the property in the file, with the format of [entity][method_name].
@Repository
public interface CustomerRepository extends CrudRepository {
List findCustomersByName(String name);
} This way we would keep the sql code separate from the java source code, in a centralized place and easy to review by a DBA.
Infinite selects, or how to run out of memory in a SELECT.
Suppose we have to generate a report in a file with the results of a query, an ORM would invite us to do something like this:
Iterable customers=customerRepository.findAll();
saveToDisk(customers) This code has one advantage: it is short and to the point. And a big disadvantage: it is a very simplified view of the problem.
Suppose our customer object were relatively large. Let’s say 16kb. And that in the table, after 3 years in production, there were 1500000. In a single call, we would occupy 20Mb of memory and the rubbish collector would have to delete it at the end of the save to disk. This is because the ORM gives us great freedom when launching this query, but if we are not very responsible, we will cause serious performance problems.
Any way to solve it? Yes, by processing the rows of the query 1 by 1. How? Well, first, forget about JPA, as you won’t find the solution there. We have two options:
- We move into the JDBC world and traverse the result with a ResultSet.
- Do it directly with Hibernate.
With Hibernate, it would be something like this:
StatelessSession session = ((Session) em.getDelegate()).getSessionFactory().openStatelessSession();
Query query = session
.createQuery("SELECT c FROM Customer c ");
query.setFetchSize(1000);
query.setReadOnly(true);
ScrollableResults results = query.scroll(ScrollMode.FORWARD_ONLY);
while (results.next()) {
Customer customer=(Customer)results.get(0);
saveToDisk(customer);
}
results.close();
session.close();Conclusion
In short, the use of ORM (Spring-Daa / JPA / Hibernate) abstracts us from the database in an attempt to simplify our work as much as possible, but the development of software that communicates with a database often requires optimisations that do not go well with simplification. And without these optimisations, developments that are carried out quickly thanks to asbtraction cause serious memory and general performance problems during maintenance.
The best tool to use during development with JPA/Hibernate is to enable direct inspection of queries from the SQL log, and understand why our ORM executes them, and if in doubt, dig up a DBA who knows what’s going on.