
Desde hace algún tiempo, vemos cómo una de las «tecnologías del futuro» se implanta cada vez más en nuestras vidas. Acercándose e involucrándose en las aplicaciones y sistemas que utilizamos en nuestro día a día, convirtiéndose en una «tecnología del presente» con gran potencial y aun mucho camino por recorrer. Hablamos de la ya famosa «Inteligencia Artificial».
Hoy en día, gran parte de la información que nos llega proviene de medios no especializados en los que, en ocasiones, encontramos más ciencia ficción o exageraciones que información veraz de lo que es esta Inteligencia Artificial.
Como ejemplo de lo anterior, recientemente aparecieron una serie de artículos en el periódico en relación con un proyecto de inteligencia artificial de Facebook wa desconectado. Algunos medios generalistas se apresuraron a dar tal noticia como si hubiera estado a punto de acabarse el mundo conocido con frases como: Facebook ha desconectado una inteligencia artificial que había «cobrado vida» o «Los ingenieros de Facebook entran en pánico y desconectan una IA (Inteligencia Artificial) porque los bots desarrollaron su propio lenguaje».
Por supuesto, esta noticia fue transgredida con sensacionalismo y no se acercó a la realidad de lo sucedido, que luego fue explicado en otros medios, como Gizmodo que publicó un artículo donde dice que la inteligencia artificial desarrollada por Facebook que se decidió apagar, lo único que la hacía diferente era comunicarse de una manera más eficiente para las máquinas, pero menos inteligible para el ser humano.
Además, se explicaba que la única razón para estar apagado era que el objetivo del proyecto era desarrollar una inteligencia artificial que pudiera comunicarse con precisión con los humanos en determinadas situaciones. Este tipo de acontecimientos no hacen más que desinformar sobre lo que es realmente la Inteligencia Artificial.
En este artículo trataré de explicar mínimamente -y de forma inteligible para el ciudadano no especializado en estos temas- una parte de lo que globalmente se conoce como Inteligencia Artificial.
Nos centraremos concretamente en el área del aprendizaje automático (machine learning). Es quizá la parte más conocida de este mundo, ya que recoge tecnologías como las redes neuronales o los problemas de clasificación y predicción.
El aprendizaje automático, a su vez, se divide en varias áreas según los algoritmos utilizados y la función a la que van dirigidos. Estas áreas son principalmente el «Aprendizaje Supervisado», el «Aprendizaje No Supervisado» y el «Aprendizaje por Refuerzo».
Existen otras áreas que no trataremos en este artículo. De hecho, nos centraremos principalmente en el aprendizaje supervisado, que entiendo que será más fácil de entender para hacerse una idea de cómo funciona este mundo de la Inteligencia Artificial.
¿Qué es y cómo funciona el aprendizaje supervisado?
Este tipo «supervisado» basa su aprendizaje en un conjunto de muestras de las que conoce los parámetros de entrada y sus valores de salida válidos y ciertos, a partir de los cuales trata de encontrar el patrón correcto para ajustarse a cualquier nueva entrada y poder Predecir su valor de salida (problemas de regresión lineal) o incluirlo en una categoría conocida (problemas de clasificación).
Como se ha mencionado mínimamente en el párrafo anterior, este tipo de aprendizaje servirá para resolver dos grandes grupos de problemas:
1.- Problemas de regresión lineal
Son aquellos en los que se pretende obtener un valor de salida para una entrada dada. Ejemplos de este tipo de problemas pueden ser:
- Intentar conocer el valor de una vivienda dada una serie de datos de entrada como los metros cuadrados, el número de habitaciones o la zona en la que se encuentra.
- Intentar predecir el desarrollo de ciertas enfermedades, ya que dada una serie de variables podríamos saber si en el futuro un paciente tiene más probabilidades de sufrir algún tipo de afección.
Los datos de entrada podrían ser: antecedentes familiares, si es fumador, si hace deporte, la cantidad de azúcar que consume en su dieta o si tiene algún tipo de marcador genético.
2.- Problemas de clasificación
They are those in which we need to frame an entry data within a category. Some examples:
- Detection systems for unwanted e-mails, where it is necessary to know if the e-mail that was just entered should be archived directly. To do this, there is input data available such as the sender, the body of the message or some keywords or links within the mail.
- Online advertising systems where different users are categorized to show them the type of advertising that is most useful.
¿Cómo enseñar a una máquina a resolver estos problemas?
A diferencia de muchos de lo que se puede esperar, para este tipo de problemas, las máquinas no aprenden o adquieren conocimientos directamente sobre su problema concreto que luego aplican. Sino que lo que necesitan es modelizar funciones matemáticas capaces de calcular la salida más probable para una entrada dada.
Regresión lineal
Por ejemplo, para los problemas de regresión lineal más básicos, lo «único» que necesitará la máquina será un algoritmo que cumpla una función lineal simple. Por ejemplo, si quisiéramos calcular el valor de una casa teniendo en cuenta el número de metros cuadrados que tiene, nuestra función principal sería:
f(x) = a +b*x
Es una función que a muchos les sonará de sus años de primaria. Pues bien, en el mundo de la inteligencia artificial se utiliza otro tipo de notación:
hq(x) = q0 + q1x
Donde «h» se conoce como hipótesis, y «q0» y «q1» como parámetros.
Los algoritmos de aprendizaje automático se encargan de modelizar la función anterior para que se ajuste lo máximo posible al conjunto de datos muestrales de los que parte, obteniendo la mínima pérdida para cada caso muestral.
Este algoritmo se basa en una función matemática conocida como función de coste (para una función dada) que debe minimizarse para obtener los valores óptimos de los parámetros «q».
Esta función es algo más compleja y no entraremos en su explicación en detalle. Simplemente, no deja de ser una función matemática que modela la función de predicción (o de regresión lineal).
Por ejemplo, en el siguiente gráfico, los puntos son la muestra dada y la línea discontinua es la función modelada:
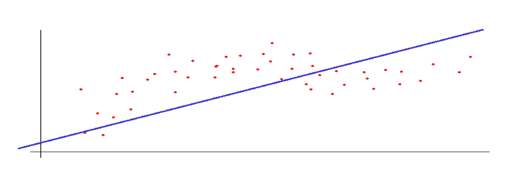
Por supuesto, la predicción anterior no parece demasiado buena para el conjunto de muestras dado, pero estamos trabajando con un único valor de entrada y sabemos que en la tasación de una vivienda intervienen múltiples factores.
Como decíamos, para hacer una mejor aproximación al caso de tasación de una vivienda, sería necesario incorporar muchos más factores además de los metros cuadrados. Como, por ejemplo, el número de habitaciones, la zona en la que se encuentra la demanda de vivienda existente en esa zona…
Para ajustar nuestra función de regresión lineal a todos estos factores de entrada, tendríamos que tenerlos en cuenta en su definición. Esto complicaría la función, con ‘n’ datos de entrada esta función podría tener este aspecto:
hq(x) = q0 + q1x1 + q2x2 + q3x3 + … + qnxn
Como puede verse, además de complicarse la función «hipótesis», también se complicará la función de coste que necesitamos para modelizar los valores de q1 q2 q3 y qn
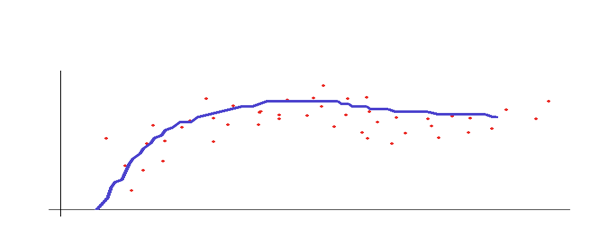
Una vez que nuestra función está bien modelada y teniendo en cuenta los valores de entrada apropiados, el gráfico de nuestra predicción podría parecerse a esto:
Problemas de clasificación
Para este tipo de problemas, en los que queremos categorizar una entrada en función de ciertos parámetros de entrada, la operación sigue basándose en la misma estrategia: modelar una función que nos permita saber si la entrada debe asignarse a una categoría o no.
Un ejemplo de este tipo de problemas sería la detección de entrada de correos no deseados a nuestra bandeja de entrada para moverlos a la carpeta «spam».
Para ello tendríamos que definir qué variables influyen a la hora de considerar que un correo es «spam» o no. Estas variables se incorporarían en una función muy similar a la anterior, pero tratando de darnos siempre como salida valores discretos ya predefinidos. Por ejemplo, 1 si es spam y 0 si no lo es.
La función básica que se utiliza para calcular estos valores es algo más compleja que la anterior:
![]()
Donde la función g (z) se define como:
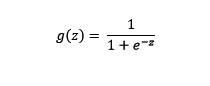
En el que, según se entiende, z sería el término anterior:
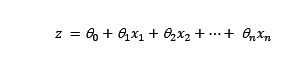
La salida de esta función siempre da un valor entre 0 y 1, donde la categorización se hará por aproximación a 0 y 1. En nuestro caso, si el valor de salida se aproxima a 1, el correo electrónico evaluado se considerará «spam».
Una vez más, el algoritmo que se utilice debe intentar minimizar la función de coste para que el resultado se adapte lo más posible a los valores de la muestra en la que se basa el aprendizaje supervisado.
Redes neuronales

Quizá este sea uno de los conceptos más famosos de la inteligencia artificial que muchos han oído, pero poco se sabe exactamente a qué se refiere.
En esencia, este concepto se refiere simplemente a un problema de clasificación. Se basa en este tipo de problemas para alcanzar niveles superiores.
Una red neuronal no es más que un conjunto de problemas de clasificación dispuestos en modo de red, donde la salida de uno de ellos se convierte en la entrada del siguiente o siguientes, que a su vez serán las entradas de otro. De este modo, se tratan los datos de entrada en múltiples niveles para obtener la salida más eficiente a la entrada dada.
El diseño de estas redes neuronales es el que dicta cómo se ordenan los pequeños problemas de clasificación para dar la solución más óptima y cómo se relacionan entre sí.
En problemas complejos o investigaciones sobre este tema, se crean redes de redes neuronales donde la salida de una es la entrada de otras, alcanzando así altos niveles de modelado de aprendizaje.
Conclusión
A través de estas breves explicaciones, he intentado demostrar que la inteligencia artificial no es algo mágico fuera de control que las máquinas crean por sí mismas, si no que se basa en fórmulas y funciones matemáticas traídas de la estadística «tradicional» para poder predecir ciertos acontecimientos.
Es cierto que estas funciones son modeladas por la propia máquina, creando a su vez otras funciones matemáticas. Esto le da el poder a este tipo de tecnología capaz de modelar funciones (algoritmos) de una forma mucho más rápida y eficiente de lo que lo puede hacer el ser humano.
También es destacable que toda la base de esta «tecnología del futuro», como la llamábamos al principio, se propuso ya en los años setenta.
Si bien es cierto que no ha sido hasta la aparición de procesadores más potentes y modos de almacenamiento de datos más robustos y eficaces cuando su desarrollo ha sido posible.
Espero haber contribuido a aclarar -de forma básica- a los interesados en el tema, cuál es la base de esta tecnología, para que la próxima vez que lean artículos en la prensa generalista, puedan detectar qué es ciencia ficción y qué es realidad.
Herramientas para la Cuarta Revolución Industrial Te contamos por qué es tan importante la neutralidad tecnológica y cómo afecta a los usuarios si no se cumple… Desmontamos 5 mitos comunes en la materiaInformación relacionada

Herramientas para la Cuarta Revolución Industrial

¿Qué es la neutralidad tecnológica?

5 Mitos sobre firma electrónica y digital