
For some time, we have seen how one of the “technologies of the future” has been implanted more and more in our lives. Approaching and getting involved in the applications and systems we use in our day to day, becoming a “technology of the present” with great potential and still a long way to go. We talk about the already-famous “Artificial Intelligence”.
Today, much of the information that comes to us comes from non-specialized media in which, at times, we find more science fiction or exaggerations than truthful information of what is this Artificial Intelligence.
As an example of the above, recently appeared a series of articles in the newspaper regarding a project of Facebook artificial intelligence wa disconnected. Some general media rushed to give such news as if it had been about to end the known world with phrases like: Facebook has turned off an artificial intelligence that had “come to life” or “Facebook engineers panic and disconnect an AI (Artificial intelligence) because the bots developed their own language.
Of course, this news was transgressed with sensationalism and did not approach the reality of what happened, which was later explained in other media, such as Gizmodo that published an article where it says that the artificial intelligence developed by Facebook that was decided to turn off, the only thing that made it different was to communicate in a more efficient way for the machines, but less intelligible for the human being.
In addition, it was explained that the only reason for being turned off was because the purpose of the project was to develop an artificial intelligence that could precisely communicate with humans in certain situations. These kinds of events do nothing but misinform what Artificial Intelligence really is.
In this article, I will try to explain in a minimal way – and in an intelligible way for the citizen who is not specialized in these subjects – a part of what is globally known as Artificial Intelligence.
We will focus specifically on the area of automatic learning (machine learning). This is perhaps the best known part of this world, since it picks up technologies such as neural networks or problems of classification and prediction.
Machine learning, at the same time, is divided into several areas according to the algorithms used and the function to which they are directed. These areas are mainly “Supervised Learning” and “Unsupervised Learning” and “Reinforcement Learning”.
There are other areas that we will not discuss in this article. In fact, we will focus mainly on supervised learning, which I understand will be easier to understand to get an idea of how this world of Artificial Intelligence works.
What is and how supervised learning works?
This “supervised” type bases its learning on a set of samples of which it knows the input parameters and their valid and certain output values, from which it tries to find the correct pattern to fit any new input and be able to Predict its output value (linear regression problems) or include it in a known category (classification problems).
As it has been mentioned minimally in the previous paragraph, this type of learning will serve to solve two large groups of problems:
1.- Linear regression problems
They are those in which it is intended to obtain an output value for a given input. Examples of such problems can be:
- Try to know the value of a house given a series of input data such as square meters, number of rooms or the area in which it is.
- Try to predict the development of certain diseases, because given a series of variables we could know if in the future a patient is more likely to suffer some type of condition.
The input data could be: family history, if he is a smoker, if he play sports, the amount of sugar he consumes in his diet or if he has some type of genetic marker.
2.- Classification problems
They are those in which we need to frame an entry data within a category. Some examples:
- Detection systems for unwanted e-mails, where it is necessary to know if the e-mail that was just entered should be archived directly. To do this, there is input data available such as the sender, the body of the message or some keywords or links within the mail.
- Online advertising systems where different users are categorized to show them the type of advertising that is most useful.
How do you teach a machine to solve these problems?
Unlike many of what you can expect, for these types of problems, the machines do not learn or acquire knowledge directly on their concrete problem that later apply. But what they need is to model mathematical functions capable of calculating the most probable output for a given input.
Linear regression
For example, for the most basic linear regression problems, the “only” thing that the machine will need will be an algorithm that fulfills a simple linear function. For example, if we wanted to calculate the value of a house considering the number of square meters it has, our primary function would be:
f(x) = a +b*x
That is a function that for many it will sound from their elementary school years. Well, in the world of artificial intelligence it uses another type of notation:
hq(x) = q0 + q1x
Where a ‘h’ is known as a hypothesis, and a q0 and q1 as parameters.
The automatic learning algorithms are responsible for modeling the previous function to match as much as possible with the set of sample data from which it sets, obtaining the minimum loss for each sample case.
This algorithm is based on a mathematical function known as a cost function (for a given function) that must be minimized to obtain the optimal values of the ‘q’ parameters.
This function is somewhat more complex and we will not go into its explanation in detail. Simply, it remains a mathematical function that models the prediction (or linear regression) function.
For example, in the following graph, the points are the given sample and the dashed line is the modeled function:
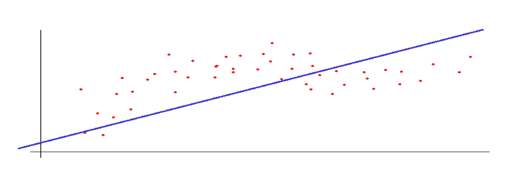
Of course, the above prediction does not seem too good for the given set of samples, but we are working with a single input value and we know that multiple factors are involved in the appraisal of a home.
As we said, to make a better approximation to the case of appraisal of a house, it would be necessary to incorporate many more factors besides the square meters. As, for example, the number of rooms, the area in which it is the existing demand for housing in that area…
To fit our linear regression function to all these input factors, we would have to take them into account in their definition. This would complicate the function, with ‘n’ input data this function could look like this:
hq(x) = q0 + q1x1 + q2x2 + q3x3 + … + qnxn
As can be seen, in addition to complicating the “hypothesis” function, it will also complicate the cost function we need to model the values of q1 q2 q3 and qn
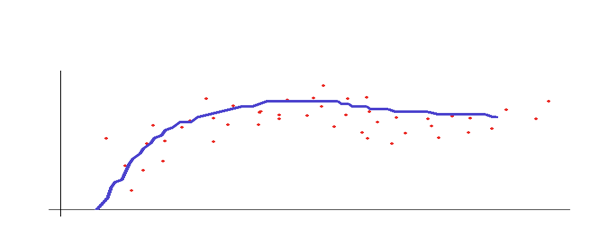
Once our function is well modeled and taking into account the appropriate input values, the graph of our prediction might look something like this:
Classification problems
For these types of problems, in which we want to categorize an input based on certain input parameters, the operation continues based on the same strategy: model a function that allows us to know if the input should be assigned to a category or not.
An example of such problems would be the detection of incoming unwanted emails to our inbox to move them to the “spam” folder.
For this we would have to define which variables influence in considering that an email is “spam” or not. These variables would be incorporate in a function very similar to the previous, but trying to always give us as output discrete values already predefined. For example, 1 if it is spam and 0 if it isn’t.
The basic function that is used to calculate these values is somewhat more complex than the previous one:
![]()
![]()
Where the function g (z) is defined as:
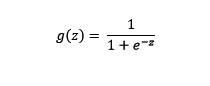
In which, as it is understood, z would be the previous term:
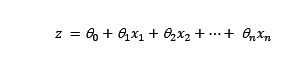
The output of this function always gives a value between 0 and 1, where the categorization will be done by approximation to 0 and 1. In our case, if the output value is closer to 1, the e-mail being evaluated will be considered a ‘spam’.
Again, the algorithm to be used should try to minimize the cost function so that the result is adapted as much as possible to the sample values on which supervised learning is based.
Neural Networks

Perhaps this is one of the most famous concepts of artificial intelligence that many have heard, but little knows exactly what it refers to.
In essence, this concept simply refers to a classification problem. It is based on these types of problems to reach higher levels.
A neural network is nothing more than a set of classification problems arranged in network mode, where the output of one of them becomes the input of the next or subsequent, which at the same time will be the inputs of another. Thereby treating the input data at multiple levels to obtain the most efficient output at the given input.
The design of these neural networks is the one that dictates how the small classification problems are arranged to give the most optimal solution and how they relate to each other.
In complex problems or investigations on this subject, they are created to create networks of neural networks d
Where the output of one is the input of others, thus reaching high levels of learning modeling.
Conclusion
Through these brief explanations, I have tried to show that artificial intelligence is not something magic out of control that machines create for themselves, but is based on formulas and mathematical functions brought from “traditional” statistics to be able to predict certain events.
It is true that these functions are modeled by the machine itself, creating in turn other mathematical functions. This gives the power to this type of technology capable of modeling functions (algorithms) in a much faster and more efficient way than human can.
It is remarkable, too, that the whole basis of this “technology of the future”, as we called it at the beginning, was proposed back in the seventies.
While it is true that it is not until the emergence of more powerful processors and data storage modes more robust and effective when its development has been possible.
I hope to have helped to clarify – in a basic way – to those interested in the subject, what is the basis of this technology, so that the next time they read articles in the general press, they can detect what is science fiction and what is reality.